

结合Spring Data Neo4j与Neo4j Java Driver在Spring Boot中处理复杂Neo4j查询
在现代数据分析和决策支持中,知识图谱的构建和查询已成为核心组成部分。本文将探讨如何在Spring Boot应用中结合使用Spring Data Neo4j和Neo4j Java Driver,以处理复杂的Neo4j查询,并确保查询结果的灵活性和高效性。
Neo4j Java Driver和Spring Data Neo4j简介
- Neo4j Java Driver: Neo4j官方提供的Java驱动程序,允许应用通过Cypher查询直接与Neo4j数据库交互,返回原始数据。。
- Spring Data Neo4j: 为Neo4j提供Spring Data支持的模块,支持Repository、对象映射以及简单的CRUD操作。
面临的问题
在程序中,仅使用Spring Data Neo4j只能处理基本操作,如创建节点、关系、删除节点和删除关系等。然而,随着程序的扩展,需要根据多个未知属性对查询节点进行过滤,并处理Cypher查询返回的复杂结果(如节点、关系及属性的集合)。Spring Data Neo4j无法高效地满足需求,因此,在Spring Boot中引入了Neo4j Java Driver,以便更灵活和高效地执行复杂的Cypher查询。
检查依赖版本
在添加Neo4j Java Driver依赖之前,需要检查其与Spring Data Neo4j的兼容性。由于Spring Data Neo4j的版本会根据Spring Boot版本自动匹配,使用Maven helper分析依赖关系,确保Neo4j Java Driver的版本与Spring Data Neo4j使用的版本一致。例如,对于Spring Boot 2.7.3,Neo4j Java Driver的兼容版本为4.4.9。 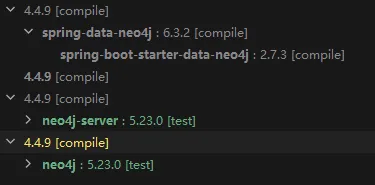
需求分析
1.动态过滤查询
在知识图谱中,每个节点不仅包含UUID等基本信息,还包含多个动态属性(如节点名称、语言等),由于额外属性的键值和数量不固定,需要构建动态查询来处理。而在Spring Data Neo4j中,无法直接在@Query注解上拼接Cypher语句。
2.处理返回结果
复杂查询(如多个节点和关系的集合)返回的数据需要根据不同类型(节点、关系)进行解析和封装。由于Spring Data Neo4j主要用于对象映射,它不能直接返回Cypher查询的原始数据。因此,我们需要手动处理查询结果,解析出节点、关系及其属性。
代码实现
1.导入neo4j-java-driver依赖
<dependency>
<groupId>org.neo4j.driver</groupId>
<artifactId>neo4j-java-driver</artifactId>
<version>4.4.9</version>
</dependency>
2.Cypher语句设计
定义三个实体类型:User、Graph 和 GraphNode。一个 User 节点可以创建一个或多个 Graph 节点,通过 RELATION 类型的关系进行连接,该关系包含属性 name = "Have"。一个 Graph 节点可以包含多个 GraphNode 节点,同样通过 RELATION 类型的关系进行连接,该关系也包含属性 name = "Have"。GraphNode 节点之间存在关系,关系类型为 RELATION,关系属性为自定义的 name。
MATCH (g:Graph { uuid: $uuid })
OPTIONAL MATCH (g)-[:RELATION]->(n:GraphNode)
OPTIONAL MATCH (n)-[r:RELATION]->(:GraphNode)
WITH DISTINCT n, COLLECT(r) AS relations
RETURN DISTINCT n, relations
Cypher语句解释
- MATCH (g
{ uuid: $uuid }):
- 匹配具有指定
uuid的Graph节点。
- OPTIONAL MATCH (g)-[
]->(n ):
- 匹配从
Graph节点出发,通过RELATION关系连接到的GraphNode节点。
- OPTIONAL MATCH (n)-[r
]->( ):
- 匹配从
GraphNode节点出发,通过RELATION关系连接到的其他GraphNode节点。
- WITH DISTINCT n, COLLECT(r) AS relations:
- 去重节点,并将关系收集到列表中。
- RETURN DISTINCT n, relations:
- 返回去重后的
GraphNode节点及其关系列表。
3.动态过滤条件
我们使用Map<String, String>来存储动态的过滤条件,并通过拼接Cypher语句来实现过滤。以下方法生成动态的过滤条件。
private static StringBuilder getFilterProperties(final String node, final Map<String, String> entries) {
return new StringBuilder()
.append("WHERE ")
.append(
entries.entrySet().stream()
.map(filter -> String.format("%s.%s = '%s'", node, filter.getKey(),
escapeSingleQuotes(filter.getValue())))
.collect(Collectors.joining(" AND "))
);
}
4.拼接Cypher语句
使用 StringBuilder 通过 append() 方法添加不同的部分,包括过滤条件、节点和关系等。StringBuilder 在多次拼接字符串时性能更好,它可以在内部缓冲区中逐步构建字符串,减少了内存分配和复制的开销。
final StringBuilder cypherQuery = new StringBuilder("MATCH (g:Graph { uuid: $uuid })")
.append(" OPTIONAL MATCH (g)-[:RELATION]->(n:GraphNode) ")
.append(properties != null && !properties.isEmpty() ?
getFilterProperties("n", properties) : "")
.append(" OPTIONAL MATCH (n)-[r:RELATION]->(:GraphNode) ")
.append(" WITH DISTINCT n, COLLECT(r) AS relations")
.append(" RETURN DISTINCT n, relations");
5.执行查询并处理结果
try (Session session = driver.session(SessionConfig.builder().build())) {
return session.readTransaction(tx -> {
final var result = tx.run(cypherQuery.toString(), Values.parameters(
"uuid", graphUuid
));
final List<RelationVO> relations = new ArrayList<>();
final List<NodeVO> nodes = new ArrayList<>();
while (result.hasNext()) {
final Record record = result.next();
final NodeVO n = nodeExtractor.extractNode(record.get("n"));
nodes.add(n);
relations.addAll(nodeExtractor.extractRelationships(record.get("relations")));
}
return new GetRelationDTO(relations, new ArrayList<>(nodes));
});
}
开启查询时,创建一个 Session 对象。它是与数据库连接的会话,用于执行事务和查询。SessionConfig.builder().build() 用于配置会话,默认情况下使用默认配置。然后启动一个事务,在事务 tx 中执行 Cypher 查询。使用 Record 对象来获取查询结果。通过 nodeExtractor 将其转换为 NodeVO 对象。然后使用 nodeExtractor.extractRelationships(record.get(Constants.RELATIONS)) 获取节点之间的关系,并将其转换为 RelationVO 对象,最后将这些对象添加到列表中。最后,返回一个包含所有节点和关系信息的 GetRelationDTO 对象。
事务
这里需要注意的是,Neo4j Java Driver 不像 Spring Data Neo4j 那样由Spring提供了@Transactional注解自动管理事务,而是需要我们手动开启事务。Neo4j Java Driver只有在Session域里的语句才会被事务管理,如果这是一个写的请求,我们需要把事务范围扩大到整个业务方法上,来保证操作的原子性,对于如何高效简洁地实现Neo4j Java Driver的事务管理,我在 使用Spring AOP + 自定义注解管理Neo4j Java Driver事务 这篇文章中有详细说明。
6.Node和Relation提取方法
public NodeVO extractNode(final Object node) {
final NodeVO nodeInfo = new NodeVO();
if (node instanceof NodeValue) {
final NodeValue nodeValue = (NodeValue) node;
final Map<String, Object> nodeMap = nodeValue.asNode().asMap();
final Map<String, String> stringNodeMap = nodeMap.entrySet().stream()
.collect(Collectors.toMap(Map.Entry::getKey, entry -> String.valueOf(entry.getValue())));
setNodeInfo(stringNodeMap, nodeInfo);
}
return nodeInfo;
}
public List<RelationVO> extractRelationships(final Value relationshipsValue) {
final List<RelationVO> relations = new ArrayList<>();
if (relationshipsValue != null) {
Optional.ofNullable(relationshipsValue.asList(Value::asRelationship))
.ifPresent(relationships -> {
for (final Relationship relationshipValue : relationships) {
final Map<String, Object> relMap = relationshipValue.asMap();
final Map<String, String> stringRelMap = relMap.entrySet().stream()
.collect(Collectors.toMap(Map.Entry::getKey,
entry -> String.valueOf(entry.getValue())));
final RelationVO relation = RelationVO.builder()
.name(stringRelMap.getOrDefault(Constants.NAME, ""))
.createTime(stringRelMap.getOrDefault(Constants.CREATE_TIME_WITHOUT_HUMP, ""))
.updateTime(stringRelMap.getOrDefault(Constants.UPDATE_TIME_WITHOUT_HUMP, ""))
.uuid(stringRelMap.getOrDefault(Constants.UUID, ""))
.sourceNode(stringRelMap.getOrDefault(Constants.SOURCE_NODE, ""))
.targetNode(stringRelMap.getOrDefault(Constants.TARGET_NODE, ""))
.build();
relations.add(relation);
}
});
}
return relations;
}
完整代码示例
public GetRelationDTO getRelationByGraphUuid(final String uuid, final Map<String, String> properties) {
final StringBuilder cypherQuery = new StringBuilder("MATCH (g:Graph { uuid: $uuid })")
.append(" OPTIONAL MATCH (g)-[:RELATION]->(n:GraphNode) ")
.append(properties != null && !properties.isEmpty() ? getFilterProperties(Constants.NODE_ALIAS_N, properties) : "")
.append(" OPTIONAL MATCH (n)-[r:RELATION]->(:GraphNode) ")
.append(" WITH DISTINCT n, COLLECT(r) AS relations")
.append(" RETURN DISTINCT n, relations");
try (Session session = driver.session(SessionConfig.builder().build())) {
return session.readTransaction(tx -> {
final var result = tx.run(cypherQuery.toString(), Values.parameters(
Constants.UUID, uuid
));
final List<RelationVO> relations = new ArrayList<>();
final List<NodeVO> nodes = new ArrayList<>();
while (result.hasNext()) {
final Record record = result.next();
final NodeVO n = nodeExtractor.extractNode(record.get("n"));
nodes.add(n);
relations.addAll(nodeExtractor.extractRelationships(record.get("relations")));
}
return new GetRelationDTO(relations, new ArrayList<>(nodes));
});
}
}
GetRelationDTO类:
public class GetRelationDTO {
private List<RelationVO> relations;
private List<NodeVO> nodes;
}
RelationVO类:
public class RelationVO {
private String uuid;
private String name;
private String createTime;
private String updateTime;
private String sourceNode;
private String targetNode;
}
NodeVO类:
public class NodeVO {
private String uuid;
private Map<String, String> properties;
private String createTime;
private String updateTime;
}
项目地址
这是一个用于构建知识图谱的Web服务,基于Neo4j数据库,结合了Neo4j Java Driver和Spring Data Neo4j的强大功能。